XML классы в Lotus/Notes
Domino
(перевод А.Булгаков)
Notes/Domino 6 усиливает
поддержку XML добавление нескольких новых LotusScript классов для экспорта, импорта и обработки XML данных. Эта статья начинает более близкий обзор этих
новых классов и содержит в себе несколько примеров кода экспорта выбранных
данных из NSF файла в DXL формат,
Domino XML language, и применение двух парсеров (синтаксических
анализаторов) поддерживаемых LotusScript: DOM парсера и SAX
парсера. Следующая статья продолжатся с примера преобразования DXL в
другие диалекты XML, особенно HTML и импортирование XML данных в NSF
формат. ( Это вторая из серии статей,
которые открывают особенности в новых LotusScript классах и расширениях LotusScript в Notes/Domino 6. Первая статья имела дело с новыми LotusScript классами для манипуляции с RichText элементами. Смотри эту статью по ссылке: LotusScript: Rich text objects in Notes/Domino 6.")
Описание XML
XML (сокращённое от Extensible Markup Language) возник
довольно быстро как промышленный стандарт и промышленно - мощное решение для
обмена данными между иным способом несовместимыми приложениями и системами.
XML это язык разметки, наподобие HTML: он добавляет тэг к содержанию документа. Но в HTML тэги фиксированные и описывают вид (представление)
содержания (это тип шрифта, размер, ширина, размещение на странице). XML тэги неограниченны и описывают структуру содержания
как части или элементы данных, называемых так, как они (тэги) относятся друг к
другу. XML это больше, чем язык, это метаязык (metalanguage)
--- язык для создания и специального документирования – цель тэгов языка
используемого для описания структуры данных.
Начиная с версии R5, Domino обеспечивает поддержку XML первой реализацией DXL классов и созданием Lotus XML Toolkit. DXL (Domino
XML Language)
- есть XML язык, специально разработанный для представления
структуры базы Domino, записанной в XML формате. DXL
обеспечивает тэги языка, которые описывают структуру каждого элемента – таких
как величины данных, тип данных, атрибуты и их величины - и связи и отношения
из этих элементов в базе NSF.
Полученные из базы данные
экспортировались в DXL, конечно, это только первый
шаг. Если вы хотите переместить эти данные в другое приложение, вы можете
переформатировать или трансформировать данные в XML язык (или его диалекты), который будет пониматься
получающим приложением. Этот процесс перевода выполняется парсером
(синтаксическим анализатором)- приложением, которое переконфигурирует установку
тэгов (таким образом и структуру) данных.
В выпуске R5 XML Toolkit поддерживал XML включением двух командных строк утилит. DXLExport and DXLImport и С++ и Java классы, которые включали парсеры, позволяющие вам
получить данные из NSF файла в XML формат. Что нового в поддержке XML в Notes/Domino 6- то, что новые LotusScript классы поддерживают полный диапазон родных XML
функций. Реализация LotusScript
более полная, чем Release 5 XML Toolkit, и вы можете вести разработку и отладку
полностью в Domino Designer.
Ядро этой новой поддержки -
новый базовый класс NotesXMLProcessor. Этот класс содержит свойства и методы,
которые наследуются несколькими обрабатывающими классами. Вы не можете
использовать NotesXMLProcessor напрямую. Вместо этого вы создаёте объекты для
одного из вторичных XML классов,
используя подходящий Create метод
класса NotesSession.
Вы можете увидеть диаграмму LotusScript классов для DXL, открыв Domino Designer 6 c домашней страницы и после показа подсказки, выбрать
Domino Objects for DXL Support. Это то, что вы увидите:
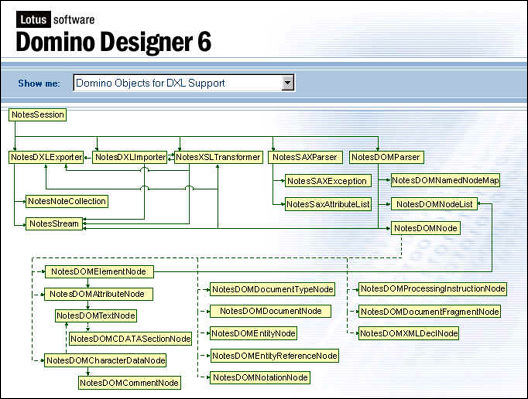
Семь наиболее важных из
представленных здесь классов являются новыми в Notes/Domino 6. Они делятся на
три основные категории:
- DXL специальные процессоры: NotesDXLExporter и NotesDXLImporter
- XML процессоры: NotesDOMParser,
NotesSAXParser и
NotesXSLTransformer
- Helper классы: NotesNoteCollection and NotesStream
Классы DXL
процессоров
Функции NotesDXLExporter and NotesDXLImporter ведут к
следующей цели: Первый конвертирует данные Domino в XML на языке DXL и другой конвертирует DXL-структурированные XML данные в данные Domino.
Классы XML
процессоров
Три следующих класса
процессора позволяют выполнять стандартные функции XML.
NotesDOMParser
XML документ объектная модель (DOM) представляет данные как структуру дерева. Все
элементы или узлы в пределах DOM дерева
могут иметь атрибуты и группироваться в отношении родитель-ребёнок к корневому
узлу, который представляет объект данных в целом. DOM парсер есть приложение, которое строит DOM дерево в памяти и
выполняет анализ проходя по этому дереву от узла к узлу. Класс
NotesDOMParser и его несколько подклассов показанные на диаграмме выше разрешают Domino выполнять эту функцию.
NotesSAXParser
SAX (как акроним «Simple API for XML») есть альтернативный метод анализа XML объекта. Раньше, чем построить DOM дерево в памяти, SAX парсер читает XML данные как поток и генерирует события, которые
обрабатываются приложением. SAX имеет
преимущества, когда вы хотите выполнить анализ сравнительно небольшой суммы
данных на выходе XML или если XML файл слишком большой, чтобы построить дерево DOM в памяти, надо напрягать все возможности компьютера
для загрузки DOM анализатора. Относительная простота SAX метода показана на диаграмме, но вы так же видите
что это недостаток - особенно, способность трансформировать данные.
NotesXSLTransformer
Почти каждый экспорт или
импорт данных включает в себя некоторые операции фильтрации и преобразования
данных. XML предоставляет решение -использования внешних документов,
записанных в XLS (XML Style Language),
контролирующих это преобразование. XLS
преобразователь может конвертировать XML
документы из одного языкового тэга в другой, фильтровать и конвертировать,
используя сущности и перестраивать структуру отношений родитель – ребёнок -
брат в данных. Таблицы стилей XLS записаны
как правильный XML.
Классы the helper
Два класса помощи особенно
полезны в XML для обрабатывающих операций,
но могут использоваться и более широко.
NotesStream
Если вы читали предшествующую
статью этой серии: LotusScript: Rich text objects in
Notes/Domino 6" вы могли распознать класс NotesStream. Класс NotesStream представляет поток двоичных или символьных данных
между Domino и файлом или областью памяти.
NotesNoteCollection
База Domino состоит из элементов дизайна и элементов данных и
известна как notes; документ есть элемент notes, как и агент, вид, ресурсы картинок и ACL листы. Методы и свойства NotesNoteCollection классов
позволяют вам создавать объекты, которые представляют все элементы в базе
данных или подмножество выбранных типов и/или создание с определённой даты
только документов notes, например, или только
элементов дизайна notes.
The pipelining function (функция конвейерной обработки)
Pipelining (конвейерная
обработка) есть ключ для работы с XML в LotusScript.
Вы можете
связывать объект процессора и helper объект вместе конвейерным способом так, что выход
первого становится входом второго. Этот способ поможет вам сохранять ваши шаги,
если вам не нужно захватывать временные результаты. Вы можете для примера,
использовать класс NotesNoteCollection для выбора документа из базы
данных, экспортировать его используя DXLExporter и конвертировать DXL в HTML используя NotesXLSTransformer.
Pipelining работает, потому что XML процессор требует от вас
идентифицировать вход и выход, перед тем, как вы вызовите метод процессора для
первого объекта на линии. Самый простой путь устанавливает pipeline (конвейер)
как специфические входы для всех процессоров, но не выходы, исключая выход
последнего процесса на линии.
Экспорт в DXL
Даже если вы не знакомы с XML, вы обратите внимание, что он выглядит как HTML – данные заключённые в тэги. Эти тэги могут включать
атрибуты, которые определяют величины. Тэги могут быть вложенными. И есть
иерархическая структура, которая обычно идентифицируется отступами.
Но типы тэгов не всегда
подобны HTML. HTML имеет ограниченное число тэгов, тогда как XML имеет неограниченное число тэгов. И где то
форматирование HTML может иметь незакрытые тэги
(вы можете использовать <p> тэг,
например для индикации параграфа, не заботясь о том, чтобы он был закрыт с
концом параграфа </p>), XML должен быть жёстко правильными: каждый открывающий
тэг, например <item>, должен сочетаться с
закрывающим тэгом, </item>.(Некоторые
тэги, как вы увидите в следующем примере сами закрываются с помощью «/>».)
XML применяет тэги в схеме,
которая описывает данные. DXL одна из
таких схем, которая описывает базы данных Domino. Тэги подобные <databaseinfo> и <aclentry>
описываются для частей структуры базы данных. Схема DXL включает в себя описание всех частей NSF файла - документов, форм, видов, агентов, acl-листов и многих других. Файл DXL представляет содержание базы данных, всё корректно
отформатированное с простым текстом. Далее представлен заголовок DXL файла:
<?xml version='1.0'
encoding='utf-8'?>
<!DOCTYPE
database SYSTEM 'xmlschemas/domino_6_0.dtd'>
<database
xmlns='http://www.lotus.com/dxl' version='6.0' replicaid='85256C7500771804'
path='dxlhelloworld.nsf' title='DXL Hello World'>
<databaseinfo dbid='85256C7500771804'
odsversion='43' diskspace='327680' percentused='86.40625'
numberofdocuments='1'>
<datamodified><datetime>20021118T165757,31-05</datetime></datamodified>
<designmodified><datetime>20021118T165803,33-05</datetime></designmodified>
</databaseinfo>
<acl maxinternetaccess='editor'>
<aclentry
name='-Default-' default='true' level='noaccess' readpublicdocs='true'
writepublicdocs='true'/>
<aclentry name='OtherDomainServers'
type='servergroup' level='noaccess' readpublicdocs='false'
writepublicdocs='false'/>
Независимо от
конечной цели форматирования, каждая операция экспорта начинается с DXL. В простейшем случае на этом
форматирование может и закончиться. Вот очень простой агент, который
экспортирует содержание базы данных как DXL. Эта часть базы данных именуемая «DXL Hello World» включается в zip файл примера для этой статьи,
который вы можете скачать из Sandbox. База данных содержит один
вид, одну форму и один документ с одним полем данных. Перед тем как открыть базу
данных «DXL Hello World», создайте директорию на вашем жёстком диске с путём
и именем: c:\dxl. Затем откройте базу данных, откройте единственный документ, и выберите
действие –«1. Экспорт DXL агент», которое запустит агент.
Агент экспорта в DXL
Агент, взятый
и адаптированный с небольшими изменениями из Domino Designer Help файла, использует объект NotesStream для чтения содержания NSF файла в dxlhelloworld_all.dml. Мы
дали файлу DXL расширение, которое возможно станет специфичным - это должно прояснить,
что файл в DXL формате. Мы выбрали XML расширение, что бы иметь выигрыш в Internet Explorer при автоматической ассоциации с
файлами типа XML и способности представлять XML файлы в хорошо отформатированном
виде. Если вы дважды кликните на файле в Windows Explorer, то он будет открыт в Internet Explorer, если это правильно составленный
XML файл. (Если это не так, вы получите сообщение об ошибке и указатель на
место в файле, где возникла ошибка. Это может помочь вам отлаживать ошибки при
создании XML файла.)
Первая часть
агента экспорта в DXL создаёт объект NotesStream, который отображает содержание
dxlhellowworld.nsf:
Sub Initialize
Dim session As
New NotesSession
Dim db As NotesDatabase
Set db = session.CurrentDatabase
Dim stream As NotesStream
Set stream = session.CreateStream
filename$ = "c:\dxl\" &
Left(db.FileName, Len(db.FileName) - 4) & "_all.dxl"
If Not stream.Open(filename$) Then
Messagebox
"Cannot open " & filename$ & ". Check to make sure this
directory exists.",, "Error"
Exit Sub
End If
Call stream.Truncate
(Метод Truncate объекта NotesStream (NotesStream.Truncate) выдаёт ошибку, если выходной файл
если выходной файл только для чтения и не может быть записан.)
Следующий
объект NotesDXLExporter установлен с двумя параметрами, входом и выходом и
процесс вызова. Отметьте, что вызов, который действительно выполняет процесс
экспорта, выполняется отдельно от специфического объекта экспорта. Это
становится важным, когда включён конвейерный режим (pipelining) и там
установлено сделать всё до начала обработки:
Dim exporter As
NotesDXLExporter
Set exporter = session.CreateDXLExporter(db, stream)
exporter.OutputDOCTYPE = False
Call exporter.Process
End
Sub
Линия exporter.OutputDOCTYPE=False поднимает некоторые глубокие вопросы о XML. Если эта
линия установлена как True (или пропущена, True установлено по умолчанию) выходной
код должен включать линию, которая
говорит:
<!DOCTYPE database SYSTEM
'xmlschemas/domino_6_0.dtd'>
Эта линия кода
вызывает декларацию DOCTYPE, указатель на файл, который определяет структуру XML документа. Эта декларация типа
документа или DTD описывает все элементы типов документов, элементы типов детей, их
порядок и число, и все атрибуты гиперссылок типа
«http://xmlwriter.net/xml_guide/attlist_declaration.shtml», сущности и другие
части документа.
Декларация DOCTYPE в Domino, для примера, описывает, что
элемент базы данных есть корневой элемент XML DOM дерева, созданного документа и что
другие декларации содержатся в файле такой же СИСТЕМЫ (SYSTEM), как документ с
путём и именем: xmlschemas/domino_6_0.dtd. На самом деле, если вы посмотрите в
вашей Notes директории, то там рядом с папками
Data, JVM и MUI вы увидите папку XMLSchemas, которая содержит файл размером 147 Кб: domino_6_0.dtd, который вы можете открыть и
читать.
Что такое DOCTYPE?
Итак, зачем
надо иметь или не иметь DOCTYPE декларацию? Есть много головоломок XML, XLS, DOM и SAX, решение которых выходит за рамки
этой статьи, и в раскрытии этого вопроса мы подходим к ним слишком близко.
Достаточно будет сказать, что есть два вида XML:
верный (valid) и закономерный (well-formed).Valid XML имеет файл DTD. Well-formed XML не имеет файла DTD, но правильно создан- все сущности
описаны, правильно закрыты и корректно вложены. Спецификация XML делает DTD необязательным. Well-formed XML само описываемый и может быть
обработан без DTD. Valid XML не может. Приложения наподобие Internet Explorer не знают как использовать ссылку на
DTD в декларации
DOCTYPE и
отказываются обрабатывать файл.
Так как
некоторые приложения, которые могут использовать Domino DXL файлы, зависят от декларации DOCTYPE, а некоторые не зависят, то XML спецификация делает её
необязательной и класс NotesDXLExpotrter поддерживает её в свойстве
OutputDOCTYPE.
Действительно,
в этом агенте, это свойство не делает каких-либо функциональных различий,
поскольку мы не совершаем каких-либо операций с выходным файлом. Но поскольку
мы хотим просматривать выходной файл в Internet Explorer, оно установлено как False. Если бы мы обрабатывали DXL другим XML процессом, мы так же должны
установить это свойство равным False. В общем случае, опускать декларацию DOCTYPE у выходного файла - это хороший
отправной пункт (как и сделано у нас в примере)
Using NotesNoteCollection
Выходом агента экспорта DXL является файл размером 40 кб. Из-за того, что он не
включает декларацию DOCTYPE, вы можете открыть его в Internet Explorer. Когда вы это сделаете, то, что вы
увидите, покажется вам знакомым - он начинается с того же самого DXL кода, пользуемого в качестве
примера в начале этой статьи (минус DOCTYPE конечно). Если вы просмотрите этот
до конца, то сможете распознать все части NSF файла – ACL, регистрационные данные, агенты,
даже иконки базы данных представлены там.
Для базы
данных, содержащий только один документ, 40 Кб возможно слишком большой размер,
нежели нужен вам. Если ваша цель не создавать точную копию NSF файла, вы можете не хотеть
экспортировать элементы дизайна, ACL данные и так далее. Место, откуда можно выбирать,
какие элементы вы хотите пропустить - класс
NotesNoteCollection.
Класс NotesNoteCollection включает в себя свойства, которые
позволяют вам выбирать элементы Notes, которые вы бы хотели включить в экспорт. Около 30
индивидуальных типов элементов Notes могут быть определены как свойства -
SelectDocuments, SelectHelpAbout, SelectSubforms и так далее. Кроме того пол
дюжины методов позволяют вам включать или исключать все типы Notes и несколько связанных с Notes типов. Метод SelectAllCodeElements,
для примера, есть выделение для агентов, скриптов базы данных, библиотеке
скриптов, данных соединения, навигации и смешанного кода элементов в базе
данных. Свойства и методы включаются и выключаются булевыми аргументами – true (значит элемент notes этого типа будет экспортирован) или
False (элемент notes этого типа не будет экспортирован).
Кроме того, булевы свойства метода CreateNoteCollection выступают в качестве основного
ключа. Вы можете установить CreateNoteCollection(false) чтобы начать ваш выбор с
нуля или CreateNoteCollection(true) чтобы начать со всех, а затем
использовать свойство для каждого типа Notes или один из методов, который
охватывает несколько типов, подготовленных вами к выбору. Например
код:
Dim nc as NotesNoteCollection
Set nc = db.CreateNoteCollection(False)
Call nc.SelectAllDesignElements(True)
Должен создать
объект NoteCollection, который включает пока только элементы дизайна
Dim nc as NotesNoteCollection
Set nc = db.CreateNoteCollection(True)
Call nc.SelectAllDesignElements(False)
Должен создать
объект NoteCollection, который включает все элементы из базы данных, исключая
элементы дизайна. Как только вы установите это свойство конструктора, объект
коллекции создаётся вызовом метода BuildCollection. Это иллюстрируется в
следующем примере:
Агент экспорта только для документов
Что бы создать
объект NoteCollection, который содержит только документы и опускает все другие
части базы данных, запускается агент экспорта в DXL только для документов в базе Hello World. Этот агент использует свойство SelectDocuments класса NotesNoteCollection.
Dim nc As NotesNoteCollection
Set nc = db.CreateNoteCollection(False)
nc.SelectDocuments=True
Call nc.BuildCollection
Объект
NotesNoteCollection задан как вход для
DXLExporter:
Dim exporter As NotesDXLExporter
Set exporter = session.CreateDXLExporter(nc, stream)
exporter.OutputDOCTYPE = False
Call exporter.Process
Результатом
действия этого агента является файл dxlhelloworld_documents.xml, который
значительно меньше, потому что он содержит только элементы, которые
представляют документы Notes (в данном случае только одну запись), корневой
элемент для файла, имя <базы данных>, которое содержит элементы документа
и конечно элементы, содержащие элемент документа. Это фактически всё, что
должно быть здесь включено:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE
database SYSTEM 'xmlschemas/domino_6_0.dtd'>
<database xmlns='http://www.lotus.com/dxl'
version='6.0' replicaid='85256C7500771804' path='dxlhelloworld.nsf' title='DXL
Hello World'>
<databaseinfo
dbid='85256C7500771804' odsversion='43' diskspace='327680'
percentused='88.828125' numberofdocuments='1'>
<datamodified>
<datetime>20021118T165757,31-05</datetime>
</datamodified>
<designmodified>
<datetime>20021125T165404,83-05</datetime>
</designmodified>
</databaseinfo>
<document
form='Hello'>
<noteinfo
noteid='8fa' unid='7C962ABED6913FAD85256C750078A86F' sequence='1'>
<created>
<datetime>20021118T165754,39-05</datetime>
</created>
<modified>
<datetime>20021118T165757,31-05</datetime>
</modified>
<revised>
<datetime>20021118T165757,30-05</datetime>
</revised>
<lastaccessed>
<datetime>20021118T165757,30-05</datetime>
</lastaccessed>
<addedtofile>
<datetime>20021118T165757,30-05</datetime>
</addedtofile>
</noteinfo>
<updatedby>
<name>CN=David
DeJean/O=DeJean</name>
</updatedby>
<item name='HelloData'>
<text>Hello
World.</text>
</item>
</document>
</database
Этот выход
вероятно всё ещё более избыточен информацией, нежели вы хотели. Но идя дальше
вам не удастся только опускать лишние элементы, необходимо будет и
редактировать структуру DXL файла. И сделать это вы можете анализатором
(парсером) данных с помощью трёх XML-парсер утилит: DOM parser, SAX
parser или XSL transformer, которые вновь пригодны в LotusScript. В этой статье мы рассмотрим DOM и SAX анализаторы, а XSL transformer рассмотрим в следующей статье этой
серии.
Using the
SAX parser
Класс NotesNoteCollection сравнительно негибкое средство
программирования. Вы можете выбрать записи, которые вы можете включить в ваш
выходной файл, и записи, которые вы хотите игнорировать, но вы не можете
изменить структуру и содержимое самих элементов, которые определены в Domino DTD. DXL файл включает не только все данные,
которые были сохранены в базе, но и все мета-данные – когда эта информация
сохранялась и модифицировалась, кто сохранил её и как она должна быть
представленна.
Эти данные
могут быть очень большими. В предыдущем примере количество данных было : “Hello World”. Она была установлена, возможно в
скрытом виде, в не меньше чем в 26 элементах мета-данных: имя базы данных и
атрибуты, databaseinfo и атрибуты, имя документа и атрибуты, и имя элемента.
Там несколько величин временных дат (datetime), два типа данных, три уникальных
идентификатора, и статистика, сколько дискового пространства занимает база
данных.
Значительная
часть этих данных необязательна для любых целей вне Domino. И всё это часто вложено в
несколько слоёв, скрывая в глубине нужный вам элемент. Элементы, именуемые <databaseinfo>, <noteinfo> и <updatedby>, для примера, все содержат
элемент базы данных. Их величины вложены в рамках элементов, которые служат в
качестве идентификаторов типа данных – datetime, текст (XML спецификация не распознаёт типы
данных и воспринимает всё как текст)
Какое решение?
Если бы DXL передатчик (transporter) мог просматривать каждый элемент в пределах Notes и на месте решать игнорировать его
или передавать его на выход в DXL файл, то это может решить проблему, но это может
сделать транспортёр слишком большим и кроме того уже есть XML процессы, которые решат эту задачу:
они называются парсерами (синтаксическими анализаторами). DOM парсер и SAX парсер используют разные модели
данных.
SAX агент-экспорт только данных
Domino SAX анализатор может генерировать 13 событий: SAX_Characters, SAX_EndDocument,
SAX_EndElement, SAX_Error, SAX_FatalError, SAX_IgnorableWhitespace,
SAX_NotationDecl, SAX_ProcessingInstruction, SAX_ResolveEntity,
SAX_StartDocument, SAX_StartElement, SAX_UnparsedEntityDecl, SAX_Warning.
LotusScript может
ответить, перехватывая каждое событие, определённой подпрограммой. Смотри
пример агента, третьего по счёту. Экспорт только данных-SAX в базы данных “DXL Hello world”. Когда вы запускаете этот агент из
меню действий, он создаёт файл dxlhelloworld_sax.xml в директории C:\dxl.
Задачей для
этого SAX-парсер агента заключается в вырезании всех метаданных для уменьшения
размера и создании выходного XML файла, который содержит только реальные данные из
базы DXL HelloWorld и лишних, как можно меньше.
Код начинается
подобно скрипту экспорта только для документов: он создаёт NotesNoteCollection, в которой содержатся только
документы и экспортирует коллекцию как DXL. Затем он связывает DXL c SAX анализатором. Связь эта
автоматическая – DXL экспортёр (DXL exporter) имеет входной аргумент (nc, см. код ниже) но не имеет
выходного аргумента. (Если бы другие объекты процессора так же были бы в
процессе перемещения (pipeline), для них так же был бы определён их вход, но не
их выход). SAX анализатор, как последний процесс в пути данных (pipeline) имеет оба
аргумента: вход для DXL Exporter является выходом для объекта NotesStream:
Sub Initialize
Dim session As
New NotesSession
Dim db As NotesDatabase
Set db = session.CurrentDatabase
'Build a NoteCollection to limit the export file to
documents
Dim nc As
NotesNoteCollection
Set nc = db.CreateNoteCollection(False)
nc.SelectDocuments=True
Call nc.BuildCollection
'Create the DXL exporter
Dim exporter As
NotesDXLExporter
Set exporter = session.CreateDXLExporter(nc)
exporter.OutputDOCTYPE = False
'Create the output file
Dim xml_out As
NotesStream
Set xml_out=session.CreateStream
filename$ = "c:\dxl\" + Left(db.FileName,
Len(db.FileName) - 4) + "_sax.xml"
If Not xml_out.Open(filename$) Then
Messagebox
"Cannot open " + filename$ + ". Check to make sure this
directory exists.",, "Error"
Exit Sub
End If
Call xml_out.Truncate
'Create the SAX parser
Dim saxParser As
NotesSAXParser
Set saxParser=session.CreateSAXParser(exporter,
xml_out)
Остаток агента
определяется связью между каждым событием SAX анализатора и сопоставленной
подпрограммой:
On Event
SAX_Characters From saxParser Call SAXCharacters
On Event SAX_EndDocument From saxParser Call
SAXEndDocument
On Event SAX_EndElement From saxParser Call
SAXEndElement
On Event SAX_Error From saxParser Call SAXError
On Event SAX_FatalError From saxParser Call
SAXFatalError
On Event SAX_IgnorableWhitespace From saxParser Call
SAXIgnorableWhitespace
On Event SAX_NotationDecl From saxParser Call SAXNotationDecl
On Event SAX_ProcessingInstruction From saxParser
Call SAXProcessingInstruction
On Event SAX_StartDocument From saxParser Call
SAXStartDocument
On Event SAX_StartElement From saxParser Call
SAXStartElement
On Event SAX_UnparsedEntityDecl From saxParser Call
SAXUnparsedEntityDecl
On Event SAX_Warning From saxParser Call SAXWarning
exporter.Process
End
Sub
(Обратите внимание, что строка, которая инициирует процесс называется exporter.Process, а не saxParser.Process. Когда вы используете
конвейерную обработку (pipelining) вы устанавливаете все объекты процесса,
затем начиная обработку вызовом первого объекта в конвейере (pipeline).
Вам не нужно
писать подпрограмму обработчик для каждого события. Этот пример агента был
адаптирован из агента в Domino Designer help файле, который вызывает окно message box для каждого события SAX. Заполненный лист даёт вам стартовую точку для вашего собственного
кода. Вы можете не заботиться о игнорируемых интервалах или сущностях (Хотя вы
вероятно захотите знать об ошибках и предупреждениях).
Каждое из этих
обработчиков событий запрашивает данные через параметры и должны явно
сгенерировать любой выход (выходной файл) с
помощью метода Output. Обработчик для символьных данных, например,
игнорирует нули, а остальные данные записывает в выходной файл в виде строки:
Sub SAXCharacters (Source As
Notessaxparser, Byval Characters As String,_
Count As Long)
If Characters
<> Chr(10) Then
Source.Output(Characters)
End If
End
Sub
С каждым
обработчиком форматирования, независимо от того, какой выход требуется,
экспортируются только данные-SAX агент-анализатор XML файла и выполняет другой XML файл. Когда подпрограмма
SAXStartDocument запущенна, он пишет XML декларацию и символ перевода
строки/каретка возвращаются в выходной файл.
Sub SAXStartDocument (Source As
Notessaxparser)
Source.Output({<?xml version='1.0'
encoding='utf-8'?>} + Chr(13)+Chr(10))
End
Sub
Подпрограмма
SAXStartElement форматирует стартовые элементы и их атрибуты, если они есть.
Она включает в себя три выражения if, которые ищут конкретные имена
элементов и выходят из подпрограммы без записи элемента в выходной файл, если
они были найдены:
Sub SAXStartElement (Source As
Notessaxparser, Byval ElementName As String, Attributes As
NotesSaxAttributeList)
If ElementName =
"databaseinfo" Then
Exit
Sub
End If
If ElementName =
"noteinfo" Then
Exit
Sub
End If
If ElementName =
"updatedby" Then
Exit
Sub
End If
Source.Output({<}+
ElementName)
Атрибуты
подпрограммы используют класс NotesSAXAttributesList, массив автоматически
создаётся анализатором, который содержит имена и значения всех элементов
атрибутов. Цикл выбирает каждый атрибут по очереди и выражение Source.Output() пишет имя атрибута, его значение
и форматирующие символы в выходной файл (output). Когда все атрибуты
обработаны, подпрограмма закрывает стартовый элемент тэгом «>» и
завершается.
Dim i As Integer
If
Attributes.Length > 0 Then
Dim attrname As
String
For i = 1 To
Attributes.Length
attrname =
Attributes.GetName(i)
Source.Output({
} + attrname+{="}+Attributes.GetValue(attrname) + {"})
Next
End If
Source.Output({>})
End
Sub
Если атрибут
имеет значение, оно появится затем как символьные данные и SAX анализатор будет генерировать
событие SAX_Characters. Подпрограмма SAX_Characters проверяет, чтобы убедиться,
что в целом контент данных не равен
Chr$(10) и если он немного больше, пишет его в выходной файл (output).
Sub SAXCharacters (Source As
Notessaxparser, Byval Characters As String,_
Count As Long)
If Characters
<> Chr(10) Then
Source.Output(Characters)
End If
End
Sub
Событие
SAX_EndElement обрабатывается подпрограммой SAXEndElement, которая содержит проверку для трёх элементов имён, которые были пропущены (условия if) в подпрограмме SAXStartElement.
Если элементы именуют как-нибудь иначе, она пишет тэг закрытия (</>) и
символ перехода на новую строку/каретку (Chr(13)+Chr(10)))возвращает в выходной файл:
Sub SAXEndElement (Source As
Notessaxparser, Byval ElementName As String)
If ElementName =
"databaseinfo" Then
Exit
Sub
End If
If ElementName =
"noteinfo" Then
Exit Sub
End If
If ElementName =
"updatedby" Then
Exit
Sub
End If
Source.Output(</}
+ ElementName + {>} + Chr(13)+Chr(10))
End
Sub
Выход этого
агента сильно подобен выходу агента экспорта только документов – даже слишком.
Вот как отобразил этот отформатированный выход Internet Explorer:
<?xml
version="1.0" encoding="utf-8" ?>
HYPERLINK
"C:\dxl\" - <database xmlns="http://www.lotus.com/dxl"
version="6.0" replicaid="85256C7500771804"
path="dxlhelloworld.nsf" title="DXL Hello World">
HYPERLINK "C:\dxl\"
- <datamodified>
<datetime>20021209T173711,55-05</datetime>
</datamodified>
HYPERLINK
"C:\dxl\" - <designmodified>
<datetime>20021210T132250,26-05</datetime>
</designmodified>
HYPERLINK
"C:\dxl\" - <document form="Hello">
HYPERLINK
"C:\dxl\" - <created>
<datetime>20021204T092656,26-05</datetime>
</created>
HYPERLINK
"C:\dxl\" - <modified>
<datetime>20021204T092658,78-05</datetime>
</modified>
HYPERLINK
"C:\dxl\" - <revised>
<datetime>20021204T092658,77-05</datetime>
</revised>
HYPERLINK "C:\dxl\"
- <lastaccessed>
<datetime>20021204T092658,77-05</datetime>
</lastaccessed>
HYPERLINK
"C:\dxl\" - <addedtofile>
<datetime>20021204T092658,77-05</datetime>
</addedtofile>
<name>CN=David
DeJean/O=DeJean</name>
HYPERLINK
"C:\dxl\" - <item name="HelloData">
<text>Hello
World.</text>
</item>
</document>
</database>
Мы удачно
удалили элементы, именуемые <databaseinfo>, <noteinfo>,
<updatedby> и их атрибуты, но их под элементы всё ещё здесь. Элементы
<datamodified> и <designmodified>, которые были детьми по
отношению к <databaseinfo>, теперь являются детьми по отношению к
<database>. Пять дата временных элементов, которые были детьми по
отношению к <noteinfo>, теперь являются детьми <document>. Элемент
<name> прежде был ребёнком у <modifiedby>, сейчас он ребёнок у того
же <document>. Что же делать?
SAX анализатор сделал в точности то, что мы ему сказали-он убрал стартовые
(<>) и конечные (</>) тэги для трёх элементов, которые мы указали.
Всё это он мог сделать, потому что знал как. Он не знает детей или
подэлементов. Он просто узнаёт события. Для многих целей и с многими XML файлами этого было бы достаточно -
просто написать, просто запустить. Но сложности DTD требуют чего-нибудь более сильного.
К счастью, мы имеем это.
Using the DOM parser
Класс
NotesDOMParser включает
DOM анализатор в
LotusScript. Код,
который содержит его, выглядит подобно
объектам NotesXMLProcessor, не сюрприз. Но функция DOM парсера очень отлична от функции SAX парсера. DOM дерево, которое строится парсером в
памяти объекта, просто не поток событий. Синтаксический анализатор затем
просматривает это дерево рекурсивно. Обработка не ограничена единственным
случаем, независимо от того, для каких данных представлены SAX события. Управление выходом может
обуславливаться существованием и содержанием других узлов в дереве.
В DOM терминологии, каждый элемент этого
дерева есть узел и имеет свои свойства. Класс LotusScript называемый NotesDOMNode
обеспечивает свойства NodeType,
используемое, чтобы идентифицировать текущий узел. Классы производные от
NotesDOMNode представляют различные типы узлов: элементы узлов, атрибуты узлов,
текст узлов и специализированные узлы, подобно XML декларации узла. Эти классы
позволяют LotusScript кодам обрабатывать
каждый экземпляр типа узла. Вместо всех обработчиков виртуальных событий,
которые были установлены для SAX парсера, DOM парсер нуждается только в одной
подпрограмме, которая просматривает дерево, проверяя тип узла, которая она
находит и берёт, вне зависимости от запрограммированного вами действия,
использование соответствующего класса.
Экспорт
только данных-DOM агент
Этот агент под
номером 4. Экспорт только данных-DOM написан, что бы решить ту же проблему, которую мы
установили для SAX анализатора - что бы выделить данные из большой массы
метаданных, кк можно эффективней. Когда вы посмотрите на код агента, вы сможете
увидеть, что он начинается точно так же, как SAX парсер скрипт: он создаёт NotesNoteCollection только для документов, и
экспортирует коллекцию как DXL. Затем он организовывает конвейерную обработку DXL, на этот раз с помощью DOM анализатора. Работа конвейерной
обработки идёт по тому же пути: DXL экспортёр имеет входной аргумент (nc), но не выходной и exporter.Process
начинает обработку.DOM анализатор берёт выход из экспортёра и превращает его в DOM дерево. Подпрограмма, называемая
walkTree просматривает дерево:
Dim docNode As NotesDOMDocumentNode
Set docNode = domParser.Document
Call walkTree(docNode)
Свойства
документа объекта NotesDOMParser
представляет корневой узел DOM дерева. Подпрограмма walkTree начинает просматривать
дерево именно с этого узла. После некоторой установки, подпрограмма начинается
с оператора Select Case. В этом выражении объект именующийся узлом, является
объектом типа NotesDOMNode. Сравниваем
величину note в выражении структуры Select Case c заданным выражением. Если это
сравнение верно, то выполняется код, содержащийся в секции конструкции Select Case:
Sub walkTree (node As NotesDOMNode)
...
If Not node.IsNull Then
Select Case node.NodeType
Фактически,
есть одно соответствие DOMNODETYPE_DOCUMENT_NODE, поскольку каждое дерево DOM имеет узел типа документ, поэтому
подпрограмма делает три вещи: первое и основное: она находит первую дочернюю
вершину узла документа и общее количество таких вершин, таким образом она может
просмотреть следующий уровень дерева:
Case DOMNODETYPE_DOCUMENT_NODE: 'It's the
Document node
'Get the number of children of Document
Set child = node.FirstChild 'Get first
child node
Dim numChildNodes As Integer
numChildNodes = node.NumberOfChildNodes
Затем,
поскольку мы форматируем выход как XML, мы пишем очень простую, но очень
необходимую XML декларацию для выходного файла (output), используя свойства класса
NotesDOMXMLDeclNode, базируется он на свойствах первого дочернего узла
документа, который всегда должен быть XML декларацией.
'Create an XML declaration for the output
Dim xNode As NotesDOMXMLDeclNode
Set xNode = node.FirstCild
domParser.Output({<?xml version="}
+ xNode.Version + {" ?>})
Наконец,
подпрограмма получает следующий узел и повторно выполняется – он вызывает себя
с дочерним объектом, теперь второй дочерний узел используется как аргумент (что
бы понять рекурсию, надо понять рекурсию). Он делает это внутри выражения
While, уменьшая номер необработанных узлов за каждую итерацию:
Call walkTree for the first child
While
numChildNodes > 0
Set child =
child.NextSibling 'Get next node
numChildNodes =
numChildNodes - 1
Call
walkTree(child)
Wend
Возможны
ещё только два случая Case (в выражении Select case) для нашего агента. Если текущий узел является
текстовым узлом с какой-нибудь величиной, но не символом перевода строки, эта величина записывается
на выход (устранение этих символов является чисто косметической операцией)-они
пришли из нескольких иначе записанных пустых полей данных Domino и появились как паразитные символы
ящика, когда выход (выходной файл) был представлен в IE, итак мы уничтожим их вот здесь:
Case DOMNODETYPE_TEXT_NODE: 'It's a plain
text node
If node.NodeValue
<> Chr(10) Then
domParser.Output(node.NodeValue)
End If
Ядро типа узла
авляется элементом notes; большинство узлов в дереве имеют этот тип; они могут иметь
как атрибуты, так и величины. Когда этот случай происходит, первым делом мы
сделаем ту же вещь, что и в подпрограмме SAX Parser StartSAXElement; мы
проверяем три имени элементов, которых мы хотим устранить и выходим из
подпрограммы без записи в выход, если найдём их. Если элемент не один из этих
трёх, мы пишем первую часть элемента тег «<» и имя элемента для выхода:
Case DOMNODETYPE_ELEMENT_NODE:
If node.NodeName = "databaseinfo" Then
Exit Sub
End If
If node.NodeName = "noteinfo" Then
Exit Sub
End IfIf node.NodeName = "updatedby" Then
Exit Sub
End If
domParser.Output({<} + node.NodeName)
Затем мы проверяем атрибуты и если элемент имеет их, мы записываем их в
выход с соответствующим форматированием и затем закрываем тэг «>»:
Dim numAttributes As Integer, numChildren
As Integer
numAttributes =
node.attributes.numberofentries
Set attrs = node.Attributes 'Get
attributes
Dim i As Integer
For i = 1 To numAttributes 'Loop through
attributes
Set a =
attrs.GetItem(i)
domParser.Output({
}+a.NodeName + {="} + a.NodeValue + {"})
Next
domParser.Output(">")
Мы
проверяем дочерние узлы и если они существуют, мы берём сначала первый и
рекурсивно снова через walkTree используя While
выражение так же, как мы делали это раньше:
numChildren = node.NumberOfChildNodes
Set child = node.FirstChild 'Get child
While numChildren > 0
Call
walkTree(child)
Set child =
child.NextSibling 'Get next child
numChildren =
numChildren - 1
Wend
Наконец, когда
все дети текущего узла были обработаны и мы вышли из выражения While, мы пишем закрывающий тэг для
элемента:
domParser.Output( {</} + node.nodeName + {>} + LF)
Когда все узлы
дерева выли обработаны, управление возвращается в главную подпрограмму Initialize на метку results.
Выходной поток закрывается и наша работа закончилась:
results:
Call outputStream.Close
Exit Sub
errh:
outputStream.WriteText ("errh:
"+Cstr(Err)+": "+Error+LF)
Resume results
End Sub
Метка err так
же является важной часть этого кода. Если в любой точке программы произошла
ошибка, номер ошибки и сообщение о ней, были бы записаны как выходной файл и
анализатор может выйти. XML анализаторы
не терпят ошибок, потому что самые частые и вероятные ошибки представляют собой
данные, которые плохо сформированы. Если данные хорошо не сформированы, это уже
не XML и это не может быть обработано. Это наглядно видно в
Web браузерах, для примера, где они являются HTML анализаторами.
Web броузеры отказоустойчивые в
определённых приделах, потому что у HTML
основная цель-представить какую-либо информацию на экране, даже если это не
очень правильное и точное представление кода.
XML с другой стороны, ставит правильность и
согласованность выше всего.
Выход (выходной файл) DOM анализатора, значительно более компактен, чем то,
что мы получили у SAX анализатора:
<?xml version="1.0" ?>
<database
path="dxlhelloworld.nsf" title="DXL Hello World"
xmlns="http://www.lotus.com/dxl" version="6.0"
replicaid="85256C7500771804">
<document
form="Hello">
<item
name="HelloData">
<text>Hello
World.</text>
</item>
</document>
</database>
Это хорошо сформированный XML. Он не включает три типа элементов, которые мы
хотели удалить. И что ещё более важно, все дочерние date/time и <name>
элементы которые SAX анализатор пропускал на
выход, были устранены как надо. Причина этого рекурсия: когда мы остановили
обработку узла, мы автоматически остановили обработку всех узлов ребёнка так
же.
SAX анализатор наоборот,
генерирует событие для всех дочерних элементов, независимо от того факта, что
их родители уже были обработаны. Мы могли бы улучшить выход SAX анализатора, если бы написали больше кода, но должны
были бы добавлять более 10 проверок if для
проверки элемента, который мы хотели устранить. Синтаксический анализатор DOM подходит для наших целей горазд лучше. В другой
ситуации это могло бы быть не так. Нет жёстких и быстрых правил выбора из этих
двух анализаторов и XSL
преобразователя, который мы подробно рассмотрим в следующей статье.
Заключение
Эта статья знакомит вас с XML и DOM
анализаторами, хотя гораздо больше здесь сказано о поддержке Domino для XML. Примеры,
представленные здесь, должны научить вас импортировать и экспортировать данные
как DXL и должны дать вам некоторые идеи, как использовать LotusScript для манипуляции XML. В следующей статье этой серии, мы рассмотрим
стилевые расширенные таблицы для трансформации DXL в другие форматы, включая HTML и другие XML
языки.